Understanding Training Testing and Validation Data
Posted by melllow thomas
Filed in Other 143 views
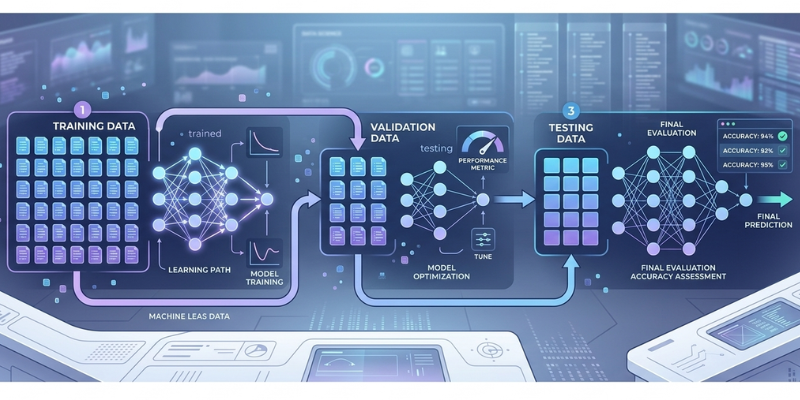
Artificial Intelligence models learn from data, but the way this data is divided plays a major role in how reliable a model becomes. Many beginners focus only on algorithms, yet the structure of the dataset often determines whether a model performs well or fails in real situations. Training, testing, and validation data are the three essential parts that help developers build trustworthy machine learning systems.
When learning how AI models are built, it is important to understand why datasets are split before training begins. Each portion of the dataset serves a different purpose during the learning process. If you want practical knowledge of these concepts and hands-on experience with real datasets, you can consider enrolling in the Artificial Intelligence Course in Trivandrum at FITA Academy to strengthen your practical skills in this field.
What is Training Data
Training data is the largest portion of a dataset, and it is used to teach a machine learning model. During training, the algorithm studies patterns, relationships, and structures within the data. The goal is to allow the model to learn how inputs relate to outputs.
For example, in an image recognition system, training data may include thousands of labeled images. Each image teaches the model what object it contains. Over time, the model begins to understand patterns that distinguish one object from another.
The more diverse and accurate the training data is, the better the model can learn meaningful patterns. Poor-quality training data can lead to weak predictions because the model learns incorrect relationships.
What is Validation Data
Validation data is used during the training process to monitor how well the model is learning. While the model studies the training data, developers periodically test its performance using the validation dataset.
This process helps detect problems such as overfitting. Overfitting occurs when a model memorizes training data instead of learning general patterns. Validation data helps developers adjust model settings so that the system performs well on unseen information.
Developers also use validation data to tune hyperparameters such as learning rate, number of layers, or decision tree depth. These adjustments improve model performance before the final evaluation stage. If you are interested in understanding how professionals fine tune models using validation datasets, take an Artificial Intelligence Course in Kochi to explore these techniques through guided training.
What is Testing Data
Testing data is the final dataset used to evaluate the completed model. Unlike validation data, the testing dataset is not used during training or model tuning. Instead, it acts as a completely unseen dataset that measures how well the model performs in real world conditions.
This stage guarantees that the model can produce precise predictions for unfamiliar data it has not seen previously. The evaluation of the system's overall performance is unbiased when utilizing testing data.
For example, a trained spam detection system can be tested with new emails that were not part of the training process. If the model correctly identifies spam and legitimate emails, it proves that the system has learned useful patterns.
Why Data Splitting Matters
Dividing datasets into training, validation, and testing sections helps create reliable Artificial Intelligence systems. Each dataset plays a unique role in the development process. Training teaches the model, validation improves the model, and testing measures the model.
Without proper data splitting, it becomes difficult to judge whether a model truly understands patterns or simply memorizes the dataset. Proper dataset management ensures fairness, reliability, and better prediction accuracy.
In many real projects, data scientists commonly use a split such as seventy percent training data, fifteen percent validation data, and fifteen percent testing data. This structure allows enough data for learning while keeping sufficient data for evaluation.
Training, validation, and testing datasets form the backbone of machine learning model development. They help models learn patterns, improve performance, and prove their accuracy in real-world scenarios. Grasping this procedure is a crucial step for anyone aiming to engage with Artificial Intelligence technologies.
As AI continues to transform industries, professionals who understand these fundamentals will have strong career opportunities. If you want to build strong practical skills in machine learning and data-driven AI systems, you can consider signing up for the Artificial Intelligence Course in Pune to begin your learning journey with structured guidance.
Also check: How Optimization Shapes Intelligent Systems